
Original post can be found on Medium.
Spoiler Alert: This blog post is not about microservice architecture or how microservices works. In this post, I will share what we have learned in scaling Realvolve CRM SaaS platform, our ongoing improvements and how Microservices architecture is playing a key role.
The Realvolve CRM SaaS Platform has experienced tremendous growth in the past 18 months. And since our launch in 2013, Realvolve has since become one of the leading Real Estate CRMs in North America.
And while some may interpret that growth as a elegant subset of features — much of it is due to a philosophical approach of our market’s needs and an eye for scale. Everyone’s definition of “scale” and “growth” can differ based on specific numbers or metric a company is targeting i.e. revenue, user base, or others. At Realvolve we are focussed in the speed to “customer success and satisfaction” growth. If our customers are happy and able to grow their business using the Realvolve CRM platform then that kind of growth makes us happy. Thus, our definition of scale & growth has the following ingredients:
- Performance i.e. Platform Speed (sub second response time)
- Stability i.e. Uptime (99.999% availability)
- New features that helps our Customers grow
- Constant Improvements i.e. enhancements and bug fixes
- User Support with quick turnaround time
- Constant upgrades in technology stack & infrastructure
- Shared learning of platform through Realvolve Facebook Community
Before I start, let me brag a little bit about our entire engineering team at Realvolve. We have hit an important milestone of 100% uptime in the past 30 days. Before that we were at 99.93% uptime on a month on month basis. (Practically, 100% uptime throughout the year is nearly impossible.)
Just to give transparency, we have witnessed 97% growth in subscriptions within the past few months.
Technology plays a very important role in this kind of scale and growth and thus we need to always stay ahead (and often catch up enhancing legacy code) for this kind of demand and growth.
Our application involves more than a dozen integrations with external services and has an inbuilt robust Workflow platform along with 45+ custom features. Our status page http://status.realvolve.com/ will shed some light on various integrations and external services in Realvolve.
Here is our tech stack of Realvolve CRM web application
- Ruby on Rails (Server-side web framework) — Rails 4.2 and Ruby 2.3.1
- Elixir and Phoenix (MicroService for BI, Notification, FileUploads, Others etc.)
- PostgreSQL (Relational database) and Follower database setup
- React.js and Redux (Javascript library for user interfaces)
- SOLR (Search engine)
- Redis (Caching)
- Sidekiq (Background jobs processing)
- Amazon Web Services & Heroku (Servers)
- Semaphore CI (Continuous Integration)
- NewRelic, Scout, Librato, Pingdom (Performance and Platform monitoring)
Performance i.e. platform speed of the SaaS application is paramount and we noticed the performance of our web application was constantly degrading as our user base grew. We were facing random crashes i.e. downtime of a couple of minutes every few months. Thus, the Performance and Uptime metric plays a very significant role in scaling SaaS web applications.
We addressed many of our scaling challenges through constant improvements in our code refactoring, database optimisations, technologies, and infrastructure upgrades along with separating a few of our core resource heavy i.e. resource intensive processes into Microservices.
Microservices are an architecture pattern that helps break down large complex systems into multiple smaller, more manageable systems. These services are built around business capabilities and independently deployable by automated deployments. Microservices can be written in different programming languages and can use different data storage technologies based on business needs.
Here are the names of a few companies successfully growing and scaling using Microservice architectural pattern.
- Netflix
- Amazon
- Uber
- Ebay
- SoundCloud
- Yelp
- Disney
- The Guardian
- Travis CI
We had a large monolith web application earlier i.e. all components and projects were running under one large server in one huge code base. We then adopted Microservices architectural pattern because it was a constant challenge managing one large monolith application. I won’t debate here whether Microservices are best or better than the Monolith application as both have their own pros and cons based on the nature of business requirements and problems/challenges we are solving. Often, the true consequences of architectural decisions are only evident several years after the decision has been made. Microservices has its own challenges for managing various moving parts of a large enterprise app but in our case it’s a “good” or “nice to have” challenge. Microservice helped us scale for our growth and to focus independently on core business needs.
One reasonable argument would be that we should not start with a microservices architecture right from the beginning of an application. Instead, it can begin with a monolith and later split it into microservices once the monolith becomes a problem.
Here is a picture depicting difference between monolith and microservices.
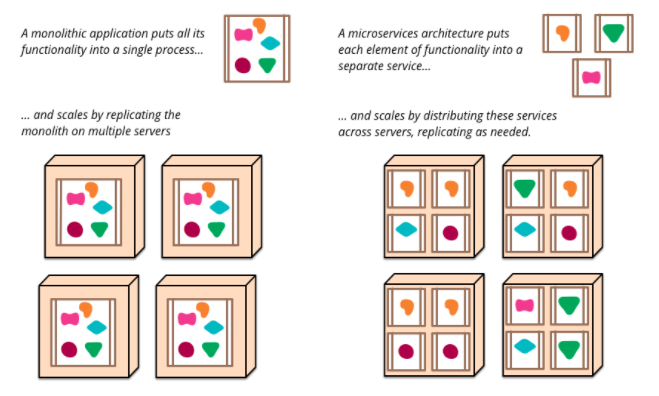 (Credits to Martin Fowler and James Lewis for this picture)
(Credits to Martin Fowler and James Lewis for this picture)
Currently, in our large enterprise app, we have separated the following functionalities and components into microservice to run as a separate process that coordinates asynchronously with the central master application and database.
- Notifications
- Incoming Emails
- Business Intelligence (BI) aggregator process
- Large File Uploads
We still have a lot of scope to separate a few more of our tightly coupled components into separate Microservices. We still need to improve one of our Microservice as it is separated but still have areas that are coupled with master application.
Here are our key takeaways while developing Microservices and improving overall system:
1. Define metrics to monitor. Following are our key metrics to monitor entire platform:
- App Server response time
- End user response on browser
- Apdex Score
- Uptime
- Request Latency
- Request Time (95th and 99th Percentile)
- Postgres Load Average
- Postgres Memory Load
- Top 20 SQL queries taking over 1 second and number of invocations
- Dyno Load Average and Dyno memory
- Number of jobs being processed in Sidekiq daily
- Sidekiq — Time taken to execute important jobs in seconds and minutes
- Sidekiq — queue growth (number of jobs getting queued for longer)
- Average Solr response times
- Redis cache size growth
- CodeClimate Issues and GPA Score
- Code Coverage (Unit Tests)
- Sidekiq failures
- Vulnerable Packages
- Open Sentry Errors and Number of Crashes
2. Setup alarms and notifications for all the key metrics mentioned in point-1 above. These alarms and notifications will notify (by email, sms and chat integrations) everybody in engineering team including key stakeholders if anything crossed the threshold limit we set or anything dropped below our configured benchmarks that needs urgent attention. We have team members in multiple countries (in various time zones) to respond to urgent issues that arise.
3. Extensively monitor platform metrics mentioned in point-1 above to know the growth in terms of usage, performance, consumption, resources etc. This will help to precisely understand bottlenecks and challenges in the system. Then respond fast by devising a plan to refactor, improve, scale, upgrade or divide the components into a microservice that needs to run as a separate component in its own workspace.
4. Do not get complacent or satisfied easily with improvements until these improvements are monitored for some extensive period of time (atleast few weeks to a month). Monitor trends and celebrate when the trend meets expected satisfaction level. Example in our case: 99.999% uptime, less than 230ms app server response time, zero crashes in a period of 60 days etc.
5. Explore, learn, and implement latest technologies that gives edge for productivity, reliability, stability, and performance. Example in our case: we developed a couple of our microservices using Elixir and Phoenix that gives us extremely solid stability, reliability, performance, and scalability.
6. Listen to customers actively and appreciate their feedback. Acknowledge it. Sometimes you won’t like the feedback but it’s the most important metric available easily to work upon i.e. the metric of “Whether your Customer is happy and able to execute work seamlessly on daily basis 24×7”. No matter how many metrics, alarms, and monitoring we have in place, it’s our Customers who give most valuable and accurate insights with our CRM platform which can help to find root cause of various challenges and bottlenecks in the system. This customer centric aspect has played the most important role in our technology improvements and initiatives. We should have our ears grounded all the time and listen to customers for bottlenecks and challenges. Our Realvolve Facebook Community has really helped us in this endeavour.
7. Attitude of Gratitude. Be thankful for all the challenges in growth and scale. This is the biggest source of learning and growth as a company and as an individual.
I would love to hear your experience with Microservices and challenges you faced scaling web applications.
The Realvolve CRM platform helps you connect, scale and flourish in your Real Estate business. You will find helpful articles here on Realvolve Blog page.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}